快一个月没写笔记了,实际上这段时间也读了一些文章。这篇文章是19年ICRL上面的工作,是关于meta learning和无监督学习的,作者在摘要中说了是要做few-shot问题的,但是全文看下来给我的感觉就是。。。强行非监督,为什么要非监督?因为作者认为这样可以学习到一个无关于具体的任务的表示能力,也就是说“学习能力”。但是文章中有一些符号错误,让我觉得这真的是顶会文章吗。。。而且在最后一层结构中的CNN用的也很迷
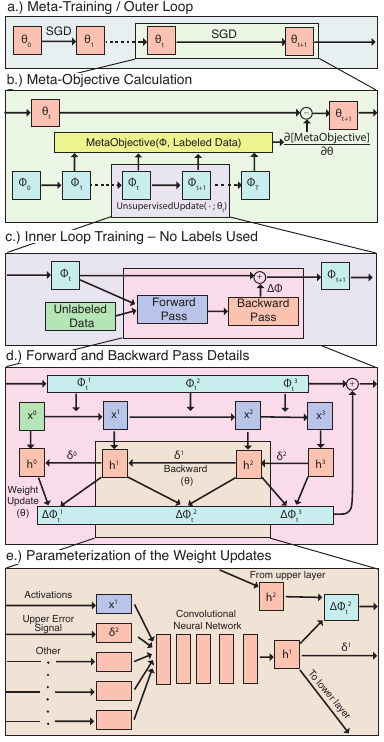
非监督学习是为了发现有益于子任务的数据表示,而不接入训练时的监督标签。提出元学习一个有益于任务的表示的非监督学习规则而非直接的着手于其后期望的任务。具体的,着手于半监督分类表现,元学习了一个非监督权重更新规则用以产生有益于任务的表示。优化目标,例如生成模型的log似然伙食重建误差,都将产生的有用表示只作为一种副作用。
然而,可以直接利用元目标 meta objective通过评估在候选任务中的有效性来获得一个由非监督的更新规则产生的表示。不像是手工设计的非监督学习规则,这个元目标直接把从无标签数据中生成的表示对于后续任务的有效性作为目标。模型设计: \(\phi\)作为多层感知机,作为\(\theta\)优化器的元参数。有监督学习:\(\phi_{t+1}={SupervisedUpdate}(\phi_t,x_t,y_t;\theta), \frac{\partial l(x,y)}{\partial \phi_t}\)。非监督学习:\(\phi_{t+1}={UnsupervisedUpdate}(\phi_t,x_t;\theta)\)
传统中,会由专家知识和朴素的超参数搜索来决定\(\theta\),而\(\theta\)包含一系列的元参数例如学习速率和正则化常数。相对的,我们的更新规则包含了更多数量级的元参数,包括神经网络权重。我们通过SGD基于元目标在内层循环训练中的总结去训练这些元参数:\(\theta^*={\arg\min}_\theta E_{task}[\sum_t{MetaObjective(\phi_t)}]\)We chose this as opposed to a convolutional model to limit the bias of convolutions in favor of learned behavior from the Unsupervised Update.
- 基础模型: 基础模型包含一个基础的全连接多层感知机,具有正则化层和ReLU层。
- 学习更新规则: 神经元局部 neuron-local 的更新规则,更新几乎只是根据激活层前后神经元活动来进行的。实际上,我们会解除这些限制并且吸收一些交叉神经信息来解除神经元的相关。在基础模型中每层\(l\)每个神经元\(i\)都有一个被称为更新网络的MLP,其输出\(h_b^li={MLP}(x_{bi}^l,z_{bi}^l,V^{l+1},\delta^{l+1};\theta)\),b代表训练小批量,输入包括,前馈激活部分\(x^l,z^l\),反馈权重\(V^l\)和错误信号\(\delta^l\)。所有更新网络共享一个元参数\(\theta\)。在非监督训练阶段,基础模型运行产生\(x^l_{bi}\),但是错误信号是由每个单元的更新网络产生的。它根据神经元隐藏状态的线性映射产生,\(\delta^l_{bi}=lin(h^l_{bi})\),用一系列学习到的反向权重backward weights\(V^l\)回传。而前向权重\(W^l\)是依赖于\(\bigtriangleup W^l_{ij}={func}(h^l_{bi},h^{l-1}_{bj},W_{ij})\)
- 元目标: 为了可以通过SGD元训练,其必须可以微分。我们根据一个batch估算分类表现,再在另一个batch上检验:\(\hat{v}={\arg\min}_v(\left\|y_a-v^Tx_a^L\right\|^2+\lambda\left\|v\right\|^2), {MetaObjective}(\dot;\phi)=CosDist(y_b,\hat{v}^Tx_b^L)\)。元目标只在元训练meta-training时被使用,内循环的训练过程是无监督更新。